This notebook contains extensive answers and tips that go beyond what was taught and what is required. But the extra parts are very useful for your future projects. Feel free to fork my repository on Github here.
Question 1 - Classification vs. Regression¶
Your goal for this project is to identify students who might need early intervention before they fail to graduate. Which type of supervised learning problem is this, classification or regression? Why?
Answer:
- This should be a classification problem.
- This is because there possibly two discrete outcomes, typical of a classification problem:
- Students who need early intervention.
- Students who do not need early intervention.
- We can classify accordingly with a binary outcome such as:
- Yes, 1, for students who need early intervention.
- No, 0, for students who do not need early intervention.
- Evidently, we are not trying to predict a continuous outcome, hence this is not a regression problem.
Exploring the Data¶
Run the code cell below to load necessary Python libraries and load the student data. Note that the last column from this dataset, 'passed', will be our target label (whether the student graduated or didn't graduate). All other columns are features about each student.
# Import libraries
import numpy as np
import pandas as pd
from time import time
from sklearn.metrics import f1_score
# Read student data
student_data = pd.read_csv("student-data.csv")
print "Student data read successfully!"
# Further Exploration using .head()
student_data.head()
# This is a 395 x 31 DataFrame
student_data.shape
# Type of data is a pandas DataFrame
# Hence I can use pandas DataFrame methods
type(student_data)
Implementation: Data Exploration¶
Let's begin by investigating the dataset to determine how many students we have information on, and learn about the graduation rate among these students. In the code cell below, you will need to compute the following:
- The total number of students,
n_students. - The total number of features for each student,
n_features. - The number of those students who passed,
n_passed. - The number of those students who failed,
n_failed. - The graduation rate of the class,
grad_rate, in percent (%).
# TODO: Calculate number of students
n_students = student_data.shape[0]
# TODO: Calculate number of features
n_features = student_data.shape[1] - 1
# TODO: Calculate passing students
# Data filtering using .loc[rows, columns]
passed = student_data.loc[student_data.passed == 'yes', 'passed']
n_passed = passed.shape[0]
# TODO: Calculate failing students
failed = student_data.loc[student_data.passed == 'no', 'passed']
n_failed = failed.shape[0]
# TODO: Calculate graduation rate
total = float(n_passed + n_failed)
grad_rate = float(n_passed * 100 / total)
# Print the results
print "Total number of students: {}".format(n_students)
print "Number of features: {}".format(n_features)
print "Number of students who passed: {}".format(n_passed)
print "Number of students who failed: {}".format(n_failed)
print "Graduation rate of the class: {:.2f}%".format(grad_rate)
Preparing the Data¶
In this section, we will prepare the data for modeling, training and testing.
Identify feature and target columns¶
It is often the case that the data you obtain contains non-numeric features. This can be a problem, as most machine learning algorithms expect numeric data to perform computations with.
Run the code cell below to separate the student data into feature and target columns to see if any features are non-numeric.
# Columns
student_data.columns
# We want to get the column name "passed" which is the last
student_data.columns[-1]
# This would get everything except for the last element that is "passed"
student_data.columns[:-1]
# Extract feature columns
# As seen above, we're getting all the columns except "passed" here but we're converting it to a list
feature_cols = list(student_data.columns[:-1])
# Extract target column 'passed'
# As seen above, since "passed" is last in the list, we're extracting using [-1]
target_col = student_data.columns[-1]
# Show the list of columns
print "Feature columns:\n{}".format(feature_cols)
print "\nTarget column: {}".format(target_col)
# Separate the data into feature data and target data (X_all and y_all, respectively)
X_all = student_data[feature_cols]
y_all = student_data[target_col]
# Show the feature information by printing the first five rows
print "\nFeature values:"
print X_all.head()
Preprocess Feature Columns¶
As you can see, there are several non-numeric columns that need to be converted! Many of them are simply yes/no, e.g. internet. These can be reasonably converted into 1/0 (binary) values.
Other columns, like Mjob and Fjob, have more than two values, and are known as categorical variables. The recommended way to handle such a column is to create as many columns as possible values (e.g. Fjob_teacher, Fjob_other, Fjob_services, etc.), and assign a 1 to one of them and 0 to all others.
These generated columns are sometimes called dummy variables, and we will use the pandas.get_dummies() function to perform this transformation. Run the code cell below to perform the preprocessing routine discussed in this section.
def preprocess_features(X):
''' Preprocesses the student data and converts non-numeric binary variables into
binary (0/1) variables. Converts categorical variables into dummy variables. '''
# Initialize new output DataFrame
output = pd.DataFrame(index = X.index)
# Investigate each feature column for the data
for col, col_data in X.iteritems():
# If data type is non-numeric, replace all yes/no values with 1/0
if col_data.dtype == object:
col_data = col_data.replace(['yes', 'no'], [1, 0])
# If data type is categorical, convert to dummy variables
if col_data.dtype == object:
# Example: 'school' => 'school_GP' and 'school_MS'
col_data = pd.get_dummies(col_data, prefix = col)
# Collect the revised columns
output = output.join(col_data)
return output
X_all = preprocess_features(X_all)
print "Processed feature columns ({} total features):\n{}".format(len(X_all.columns), list(X_all.columns))
Implementation: Training and Testing Data Split¶
So far, we have converted all categorical features into numeric values. For the next step, we split the data (both features and corresponding labels) into training and test sets. In the following code cell below, you will need to implement the following:
- Randomly shuffle and split the data (
X_all,y_all) into training and testing subsets.- Use 300 training points (approximately 75%) and 95 testing points (approximately 25%).
- Set a
random_statefor the function(s) you use, if provided. - Store the results in
X_train,X_test,y_train, andy_test.
Pro Tip: Data assessment's impact on train/test split
- When dealing with the new data set it is good practice to assess its specific characteristics and implement the cross validation technique tailored on those very characteristics, in our case there are two main elements:
- Our dataset is small.
- Our dataset is slightly unbalanced. (There are more passing students than on passing students)
What can we do?
- We could take advantage of K-fold cross validation to exploit small data sets
- Even though in this case it might not be necessary, should we have to deal with heavily unbalance datasets, we could address the unbalanced nature of our data set using Stratified K-Fold and Stratified Shuffle Split Cross validation, as stratification is preserving the preserving the percentage of samples for each class
# TODO: Import any additional functionality you may need here
from sklearn.cross_validation import train_test_split
# For initial train/test split, we can obtain stratification by simply using stratify = y_all:
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, stratify = y_all, test_size=95, random_state=42)
# Show the results of the split
print "Training set has {} samples.".format(X_train.shape[0])
print "Testing set has {} samples.".format(X_test.shape[0])
# To double check stratification
print np.mean(y_train == 'no')
print np.mean(y_test == 'no')
Training and Evaluating Models¶
In this section, you will choose 3 supervised learning models that are appropriate for this problem and available in scikit-learn. You will first discuss the reasoning behind choosing these three models by considering what you know about the data and each model's strengths and weaknesses. You will then fit the model to varying sizes of training data (100 data points, 200 data points, and 300 data points) and measure the F1 score. You will need to produce three tables (one for each model) that shows the training set size, training time, prediction time, F1 score on the training set, and F1 score on the testing set.
The following supervised learning models are currently available in scikit-learn that you may choose from:
- Gaussian Naive Bayes (GaussianNB)
- Decision Trees
- Ensemble Methods (Bagging, AdaBoost, Random Forest, Gradient Boosting)
- K-Nearest Neighbors (KNeighbors)
- Stochastic Gradient Descent (SGDC)
- Support Vector Machines (SVM)
- Logistic Regression
Question 2 - Model Application¶
List three supervised learning models that are appropriate for this problem. For each model chosen
- Describe one real-world application in industry where the model can be applied. (You may need to do a small bit of research for this — give references!)
- What are the strengths of the model; when does it perform well?
- What are the weaknesses of the model; when does it perform poorly?
- What makes this model a good candidate for the problem, given what you know about the data?
How do we choose algorithms?
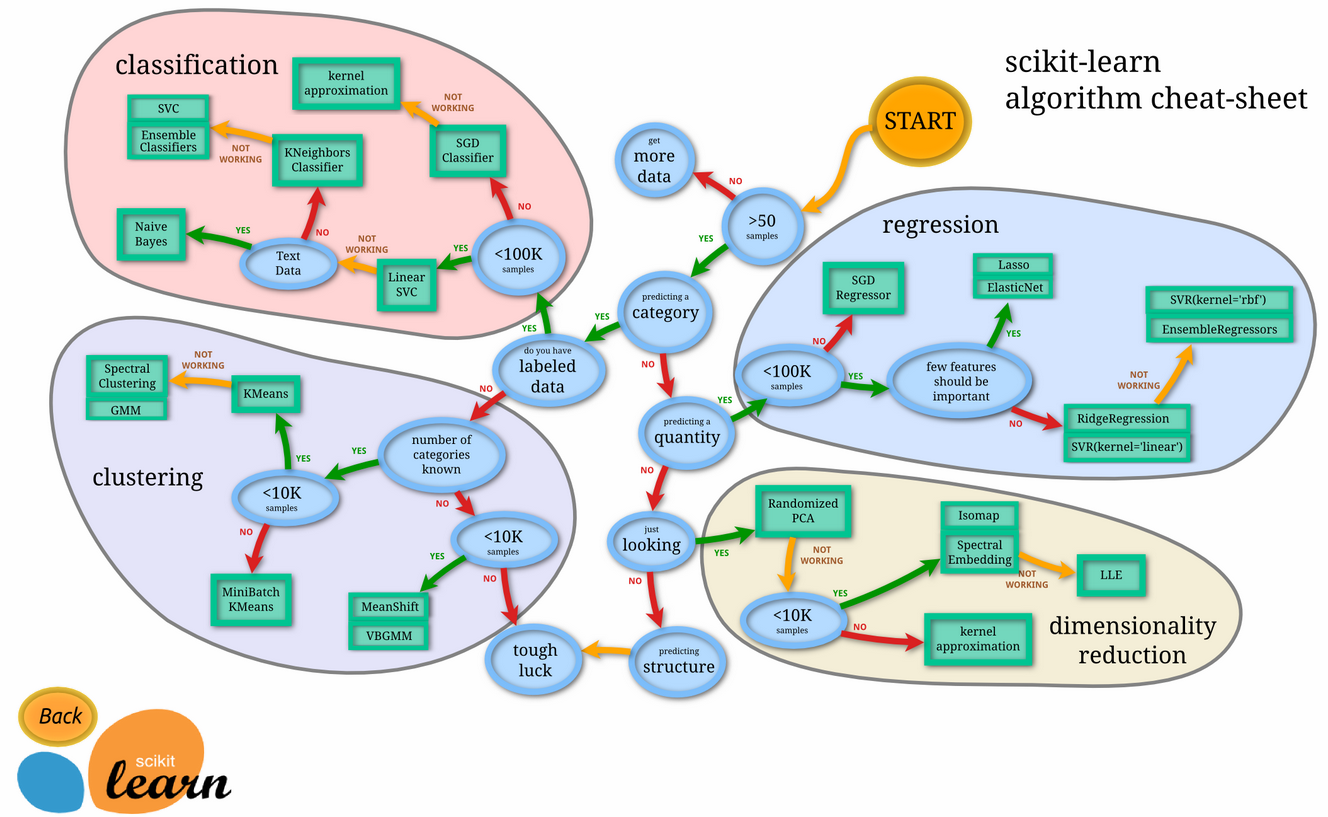
Answer:
- We will be covering 3 supervised learning models.
- Naive Bayes
- Logistic Regression
- Support Vector Machines
- But before we move on to cover the 3 supervised learning models, we will be discussing about the data itself because it is an important discussion to determine if the model makes a good candidate for the problem at hand.
DATA OVERVIEW
1. Skewed classes:
- As we can see, there is almost twice as many students who passed compared to students who failed.
- Number of students who passed: 265 (majority class)
- Number of students who failed: 130 (minority class)
- This would pose problems when we are splitting the data.
- The training test could be populated with mostly the majority class and the testing set could be populated with the minority class. This would affect the accuracy calculated.
- Hence, there should be emphasis on how we split the data and which metric to choose.
- Splitting the data: Stratified KFold
- Metrics to choose
2. Lack of data:
- There is a lack of examples in the dataset.
- 395 students
- This would have implications on some algorithms that require more data.
- Generally we want more data, except when we are facing a high bias problem.
- In this case, we should keep to simpler algorithms.
3. Too many features:
- For such a small dataset with 395 students, we have a staggeringly high number of features.
- 48 features
- Curse of Dimensionality
- For each additional feature we add, we need to increase the number of examples we have exponentially due to the curse of dimensionality.
EXPLANATION OF MODELS
1. Naive Bayes
- Industry usage (Barbosa et. al 2014)
- Classifying eggs
- There is an interesting use of naive bayes (NB) as a learning algorithm to classify eggs into 2 groups:
- Free-range eggs
- These are eggs from hens who are able to roam freely
- Battery eggs
- These are eggs from hens who are kept in a small cage. Some may call this "unethical eggs"
- Free-range eggs
- The study revealed that NB provided a high accuracy of 90% when classifying between the 2 groups of eggs.
- Strengths
- Converges quicker than discriminative models like Logistic Regression hence less data is required
- Weaknesses
- Requires observations to be independent of one another
- But in practice, the classifier performs quite well even when the independence assumption is violated
- Simple representation without opportunities for hyperparameter tuning
- Requires observations to be independent of one another
- Suitability for the problem
- This algorithm performs well for this problem because the data has the following properties:
- Low number of observations
- Naive bayes performs well on small datasets
- Low number of observations
- This algorithm performs well for this problem because the data has the following properties:
2. Logistic Regression
- Industry usage (Penderson et. al 2014)
- Classification of protein sequences
- Identify and automatically categorize protein sequences into one of 11 pre-defined classes
- Tremendous potential for further bioinformatics applications using Logistic Regression
- Classification of protein sequences
- Strengths
- Many ways to regularize the model to tolerate some errors and avoid over-fitting
- Unlike Naive Bayes, we do not have to worry about correlated features
- Unlike Support Vector Machines, we can easily take in new data using an online gradient descent method
- Weaknesses
- Requires observations to be independent of one another
- It aims to predict based on independent variables, if there are not properly identified, Logistic Regression provides little predictive value
- Suitability for the problem
- Many features may be correlated
- And Logistic Regression, unlike Naive Bayes, can deal with this problem
- Regularization to prevent overfitting due to dataset having many features
- Many features may be correlated
3. Support Vector Machines (SVMs)
- Industry usage (Di Pillo et. al 2016):
- Sales forecasting when running promotions
- Originally, statistical methods like ARIMA and smoothing methods are used like Exponential Smoothing
- But they could fail if high irregularity of sales are present
- Hence SVMs provide a good alternative
- Sales forecasting when running promotions
- Strengths
- SVM have regularization parameters to tolerate some errors and avoid over-fitting
- Kernel trick: Users can build in expert knowledge about the problem via engineering the kernel
- Provides a good out-of-sample generalization, if the parameters C and gamma are appropriate chosen
- In other words, SVM might be more robust even when the training sample has some bias
- Weaknesses
- Bad interpretability: SVMs are black boxes
- High computational cost: SVMs scale exponentially in training time
- Users might need to have certain domain knowledge to use kernel function
- Suitability for the problem
- Many features may be correlated
- Regularization to prevent overfitting due to dataset having many features
- Many features may be correlated
Works Cited
- Barbosa, R. M., Nacano, L. R., Freitas, R., Batista, B. L. and Barbosa, F. (2014), The Use of Decision Trees and Naïve Bayes Algorithms and Trace Element Patterns for Controlling the Authenticity of Free-Range-Pastured Hens’ Eggs. Journal of Food Science, 79: C1672–C1677. http://dx.doi.org/10.1111/1750-3841.12577.
- Pedersen, B. P., Ifrim, G., Liboriussen, P., Axelsen, K. B., Palmgren, M. G., Nissen, P., . . . Pedersen, C. N. S. (2014). Large scale identification and categorization of protein sequences using structured logistic regression. PloS One, 9(1), 1. http://dx.doi.org/10.1371/journal.pone.0085139
- Di Pillo, G., Latorre, V., Lucidi, S. et al. 4OR-Q J Oper Res (2016) 14: 309. http://dx.doi.org/10.1007/s10288-016-0316-0
Setup¶
Run the code cell below to initialize three helper functions which you can use for training and testing the three supervised learning models you've chosen above. The functions are as follows:
train_classifier- takes as input a classifier and training data and fits the classifier to the data.predict_labels- takes as input a fit classifier, features, and a target labeling and makes predictions using the F1 score.train_predict- takes as input a classifier, and the training and testing data, and performstrain_clasifierandpredict_labels.- This function will report the F1 score for both the training and testing data separately.
def train_classifier(clf, X_train, y_train):
''' Fits a classifier to the training data. '''
# Start the clock, train the classifier, then stop the clock
start = time()
clf.fit(X_train, y_train)
end = time()
# Print the results
print "Trained model in {:.4f} seconds".format(end - start)
def predict_labels(clf, features, target):
''' Makes predictions using a fit classifier based on F1 score. '''
# Start the clock, make predictions, then stop the clock
start = time()
y_pred = clf.predict(features)
end = time()
# Print and return results
print "Made predictions in {:.4f} seconds.".format(end - start)
return f1_score(target.values, y_pred, pos_label='yes')
def train_predict(clf, X_train, y_train, X_test, y_test):
''' Train and predict using a classifer based on F1 score. '''
# Indicate the classifier and the training set size
print ""
print "Training a {} using a training set size of {}. . .".format(clf.__class__.__name__, len(X_train))
# Train the classifier
train_classifier(clf, X_train, y_train)
# Print the results of prediction for both training and testing
print "F1 score for training set: {:.4f}.".format(predict_labels(clf, X_train, y_train))
print "F1 score for test set: {:.4f}.".format(predict_labels(clf, X_test, y_test))
Implementation: Model Performance Metrics¶
With the predefined functions above, you will now import the three supervised learning models of your choice and run the train_predict function for each one. Remember that you will need to train and predict on each classifier for three different training set sizes: 100, 200, and 300. Hence, you should expect to have 9 different outputs below — 3 for each model using the varying training set sizes. In the following code cell, you will need to implement the following:
- Import the three supervised learning models you've discussed in the previous section.
- Initialize the three models and store them in
clf_A,clf_B, andclf_C.- Use a
random_statefor each model you use, if provided. - Note: Use the default settings for each model — you will tune one specific model in a later section.
- Use a
- Create the different training set sizes to be used to train each model.
- Do not reshuffle and resplit the data! The new training points should be drawn from
X_trainandy_train.
- Do not reshuffle and resplit the data! The new training points should be drawn from
- Fit each model with each training set size and make predictions on the test set (9 in total).
Note: Three tables are provided after the following code cell which can be used to store your results.
# TODO: Import the three supervised learning models from sklearn
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# TODO: Initialize the three models
clf_A = GaussianNB()
clf_B = LogisticRegression(random_state=42)
clf_C = SVC(random_state=42)
# TODO: Set up the training set sizes
X_train_100 = X_train.iloc[:100, :]
y_train_100 = y_train.iloc[:100]
X_train_200 = X_train.iloc[:200, :]
y_train_200 = y_train.iloc[:200]
X_train_300 = X_train.iloc[:300, :]
y_train_300 = y_train.iloc[:300]
# TODO: Execute the 'train_predict' function for each classifier and each training set size
# train_predict(clf, X_train, y_train, X_test, y_test)
for clf in [clf_A, clf_B, clf_C]:
print "\n{}: \n".format(clf.__class__.__name__)
for n in [100, 200, 300]:
train_predict(clf, X_train[:n], y_train[:n], X_test, y_test)
Classifer 1 - Naive Bayes
| Training Set Size | Training Time | Prediction Time (test) | F1 Score (train) | F1 Score (test) |
|---|---|---|---|---|
| 100 | 0.0012 | 0.0003 | 0.7752 | 0.6457 |
| 200 | 0.0026 | 0.0002 | 0.8060 | 0.7218 |
| 300 | 0.0008 | 0.0003 | 0.8134 | 0.7761 |
Classifer 2 - Logistic Regression
| Training Set Size | Training Time | Prediction Time (test) | F1 Score (train) | F1 Score (test) |
|---|---|---|---|---|
| 100 | 0.0020 | 0.0001 | 0.8671 | 0.7068 |
| 200 | 0.0018 | 0.0001 | 0.8211 | 0.7391 |
| 300 | 0.0034 | 0.0002 | 0.8512 | 0.7500 |
Classifer 3 - Support Vector Machines
| Training Set Size | Training Time | Prediction Time (test) | F1 Score (train) | F1 Score (test) |
|---|---|---|---|---|
| 100 | 0.0011 | 0.0007 | 0.8366 | 0.8025 |
| 200 | 0.0043 | 0.0011 | 0.8552 | 0.8105 |
| 300 | 0.0066 | 0.0019 | 0.8615 | 0.8052 |
Choosing the Best Model¶
In this final section, you will choose from the three supervised learning models the best model to use on the student data. You will then perform a grid search optimization for the model over the entire training set (X_train and y_train) by tuning at least one parameter to improve upon the untuned model's F1 score.
Question 3 - Choosing the Best Model¶
Based on the experiments you performed earlier, in one to two paragraphs, explain to the board of supervisors what single model you chose as the best model. Which model is generally the most appropriate based on the available data, limited resources, cost, and performance?
Answer:
The predictive performance of SVMs is slightly better than Naive Bayes. However, it is important to note how SVMs' computational time would grow much faster than Naive Bayes with more data, and our costs would increase exponentially when we have more students. On the other hand, Naive Bayes' computational time would grow linearly with more data, and our cost would not rise as fast. Hence, Naive Bayes offers a good alternative to SVMs taking into account its performance on a small dataset and on a potentially large and growing dataset.
Consequently, we compare Naive Bayes and Logistic Regression. Although the results show Logistic Regression is slightly worst than Naive Bayes in terms of it predictive performance, slight tuning of Logistic Regression's model would easily yield much better predictive performance compare to Naive Bayes. This is in contrast to Naive Bayes where we do not have the opportunity to tune model. Hence, we should go with Logistic Regression.
Big O Notation for the 3 Algorithms
- Naive Bayes:
- O(n)
- Logistic Regression:
- O(C^n)
- Support Vector Machines:
- O(n^3) with sigmoid kernel
- O(n^2) with space complexities
Question 4 - Model in Layman's Terms¶
In one to two paragraphs, explain to the board of directors in layman's terms how the final model chosen is supposed to work. Be sure that you are describing the major qualities of the model, such as how the model is trained and how the model makes a prediction. Avoid using advanced mathematical or technical jargon, such as describing equations or discussing the algorithm implementation.
Answer:
First, the model learns how a student's performance indicators lead to whether a student will graduate or otherwise. The model can do this because we already have existing data on students who have and have not graduated, so our model can learn the performance indicators of those students. Based on the student's performance indicators, the model would output a weight for each performance indicator.
With this in mind, the second step is predicting whether new students would graduate or otherwise. This time we do not have information on existing students whether they have graduated or not as they are still studying. However, we have a model that learned from previous batches of students who graduated. The new students' performance indicators with their respective weights will be fed into our model and the model will output a probability and students will be classified according to whether they are "likely to graduate" or "unlikely to graduate". We can then take preventive measures on students who are unlikely to graduate.
Moreover, if we would like to play it safe and ensure that we spot as many students as we can who are "unlikely to graduate", even if they may be "likely to graduate", we can increase our strictness in determining their likelihood of graduating, and spot more of them. This is because there is no harm in flagging a student who is "likely to graduate" as "unlikely to graduate". But there may be severe repercussions if we flag a student who is "unlikely to graduate" as "likely to graduate" and do not attend to the student.
Implementation: Model Tuning (Logistic Regression)¶
Fine tune the chosen model. Use grid search (GridSearchCV) with at least one important parameter tuned with at least 3 different values. You will need to use the entire training set for this. In the code cell below, you will need to implement the following:
- Import
sklearn.grid_search.gridSearchCVandsklearn.metrics.make_scorer. - Create a dictionary of parameters you wish to tune for the chosen model.
- Example:
parameters = {'parameter' : [list of values]}.
- Example:
- Initialize the classifier you've chosen and store it in
clf. - Create the F1 scoring function using
make_scorerand store it inf1_scorer.- Set the
pos_labelparameter to the correct value!
- Set the
- Perform grid search on the classifier
clfusingf1_scoreras the scoring method, and store it ingrid_obj. - Fit the grid search object to the training data (
X_train,y_train), and store it ingrid_obj.
Pro Tip:
- We can use a stratified shuffle split data-split which preserves the percentage of samples for each class and combines it with cross validation. This could be extremely useful when the dataset is strongly imbalanced towards one of the two target labels
- http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.StratifiedShuffleSplit.html
# TODO: Import 'GridSearchCV' and 'make_scorer'
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.cross_validation import StratifiedShuffleSplit
# Create the parameters list you wish to tune
C = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
solver = ['sag']
max_iter = [1000]
param_grid = dict(C=C, solver=solver, max_iter=max_iter)
# Initialize the classifier
clf = LogisticRegression(random_state=42)
# Make an f1 scoring function using 'make_scorer'
f1_scorer = make_scorer(f1_score, pos_label='yes')
# Stratified Shuffle Split
ssscv = StratifiedShuffleSplit(y_train, n_iter=10, test_size=0.1)
# TODO: Perform grid search on the classifier using the f1_scorer as the scoring method
grid_obj = GridSearchCV(clf, param_grid, cv=ssscv, scoring=f1_scorer)
# TODO: Fit the grid search object to the training data and find the optimal parameters
grid_obj = grid_obj.fit(X_train, y_train)
# Get the estimator
clf = grid_obj.best_estimator_
# Report the final F1 score for training and testing after parameter tuning
print "Tuned model has a training F1 score of {:.4f}.".format(predict_labels(clf, X_train, y_train))
print "Tuned model has a testing F1 score of {:.4f}.".format(predict_labels(clf, X_test, y_test))
Scikit-learn's Pipeline Module: GridSearch Your Pipeline
Question 5 - Final F1 Score¶
What is the final model's F1 score for training and testing? How does that score compare to the untuned model?
Answer:
- The final model's F1 scores are:
- Training F1 score: 0.8040
- Testing F1 score: 0.8050
- There is an increase in the testing F1 score of the tuned model compared to the untuned model
- It is now higher than Naive Bayes' F1 score